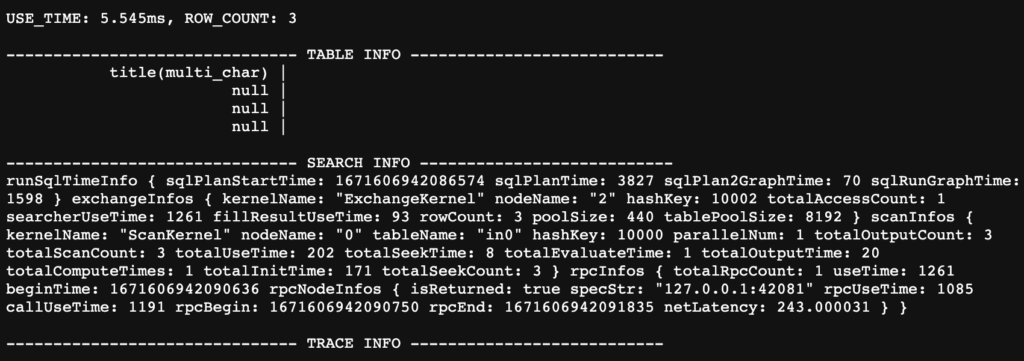
python curl_http.py <qrsHttpPort> "query=select count(*) from in0"
python curl_http.py <qrsHttpPort> "query=select id,hits from in0 where MATCHINDEX('title', '搜索词典')"
python curl_http.py <qrsHttpPort> "query=select title, subject from in0_summary_ where id=1 or id=2"